
A Brief Tour of Linux Security Modules

I’m guessing, if you’re reading this post, you already have some familiarity with Linux Security Modules (LSMs). If you’ve used SELinux or AppArmor then you’ve used an LSM. If you’ve used any modern Linux distribution or Android-based device, you’ve (probably) used an LSM.
In kernel version 5.4 there are eight LSMs—SELinux, SMACK, AppArmor, TOMOYO, Yama, LoadPin, SafeSetID, and Lockdown. There are also LSMs under development, such as SARAand KRSI, which may soon take their place in the kernel sources alongside the others. If you’re a systems or software engineer who is concerned about security—hopefully all systems and software engineers—it is worthwhile to understand why there is such a variety of LSMs. Some solve a common problem in unique ways while others address specific problems. Awareness of these differences can only increase our understanding of the security features and challenges in Linux systems.
What are LSMs?
An LSM is code compiled directly into the Linux kernel that, utilizing the LSM framework, can deny a process access to important kernel objects. The types of objects protected include files, inodes, task structures, credentials, and interprocess communication objects. Manipulating these objects represents the primary way processes interact with their environment, and by carefully specifying allowable interactions, a security administrator can make it more difficult for an attacker to exploit a flaw in one program to pivot to other areas of the system.
The first, and arguably still most prevalent, use case for the LSM framework is to implement Mandatory Access Control (MAC) policies. It should come as no surprise that there are several approaches on how to best implement MACs in the kernel. In 2001, Peter Loscocco from the National Security Agency presented one of the first implementations at the Linux 2.5 Kernel Summit. Jonathan Corbet of Linux Weekly News noted afterwards:
Perhaps the most interesting thing to come out of this discussion was the observation that there are a number of security-related projects doing similar work. All would like to see that work in the standard kernel someday. For now, however, it is very hard to know what the shape of a standard Linux high-security mechanism should really be. So the developers would really like to see the security projects get together and define a set of standard interfaces which will allow them all to hook into the kernel, so that users can experiment with more than one of them. That does not look like an easy project, don’t expect to see it anytime all that soon.
A few years later the “set of standard interfaces” became the LSM framework. As of version 5.4, the framework currently includes 224 hook points throughout the kernel, an API for registering functions to be called at these hook points, and an API for reserving memory associated with protected kernel objects for use by the LSMs. By the 2.6 kernel release at the end of 2003, both the LSM framework and SELinux (modified to use the framework instead of directly patching the kernel) were merged. While the details of the LSM implementation continue to change over time, the basic intent remains to allow fine-grained control over access to important kernel objects.
The current LSM framework allows a user to compile into the kernel multiple LSMs that can then be stacked and used simultaneously. The diagram below shows a coarse call flow for an open() where three LSMs have registed hooks:
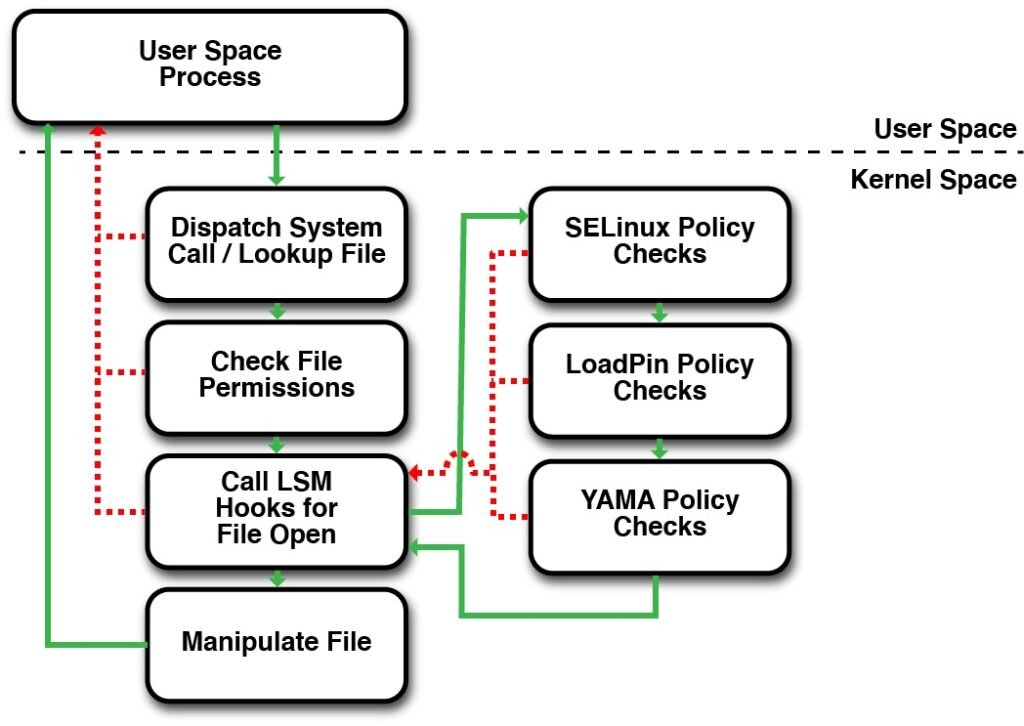
An LSM’s place in an open system call
A process in user space calls
open()on a file path.The system call is dispatched and the path string is used to obtain a kernel file object. If the parameters are incorrect an error is returned.
The “normal” Discretionary Access Control file permissions are checked. Does the current user have permission to open the requested file? If not, the system call is terminated and an error is returned to the user.
If DACs are satisfied, the LSM framework calls each of the file_open hooks for the enabled LSMs. The system call is terminated and an error returned to the user if a single LSM hook returns an error.
Finally, if all the security checks pass, the file is opened for the process, and a new file descriptor is returned to the process in user space.
Major, Minor, and Exclusive LSMs
With our basic understanding of what an LSM is, we can turn our attention to what the different LSMs in the kernel actually do. To start, let’s look at the legacy “major LSMs.” These LSMS—SELinux, SMACK, AppArmor, and TOMOYO—are all implementations of MAC with configurable policies loaded from user space. They are solving the same problem in unique ways.
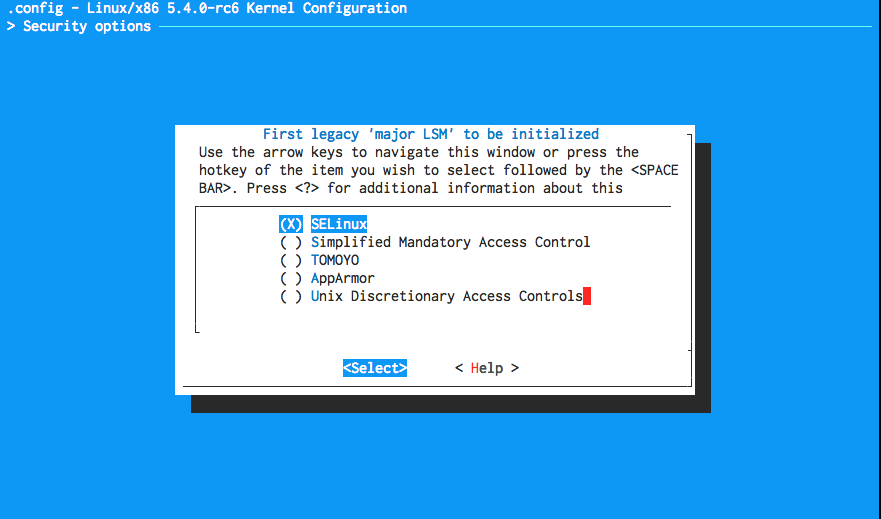
Kernel menuconfig option to select the default major LSM
The legacy major LSMs historically could not be loaded at the same time. This is because the original designers of the LSM framework allowed for only a single LSM to be enabled. The major LSMs all assumed they had exclusive access to the security context pointers and security identifiers embedded in protected kernel objects. Therefore, only a single major LSM could be used at a time, which could be configured as a kernel compile time option, as seen in the figure below, or passed as a parameter on the kernel command line.
The LSM framework continues to be modified to eliminate this distinction between “major” and “minor” LSMs. The preferred way to distinguish LSMs now is with the flag LSM_FLAG_EXCLUSIVE to be more clear that the major / minor distinction is really about exclusivity. A user can configure any number of LSMs as long as only one of them has LSM_FLAG_EXCLUSIVE set. Currently only SELinux, SMACK, and AppArmor are marked exclusive but AppArmor will soon lose that distinction and the others will follow.
The minor LSMs not only are easier to stack because they need less context, they also hard-code the majority of their policy directly in the code. The minor LSMs typically only contain flags to enable / disable options as opposed to having policy files that are loaded from user-space as part of system start.
SELinux – Security Enhanced Linux
First merged as part of Linux 2.6, SELinux is the default MAC implementation on RedHat-based Linux Distributions. It is known for being powerful and complex.
SELinux is attribute-based which means the security identifiers for files are stored in extended file attributes in the file system. For example, you can use ls -Z to see the security context on /bin/bash, which in the example below is system_u:object_r:shell_exec_t:s0. The four fields are separated by colons and are user:role:type:level.
$ ls -Z /bin/bash
-rwxr-xr-x. root root system_u:object_r:shell_exec_t:s0 /bin/bash
Click to download the full whitepaper
The most common way to specify policies in SELinux is to specify what actions SELinux subjects (or users in this case) are allowed to take on objects labeled with a particular type. Looking again at the above ls output, the classic DAC permissions indicate that all users on the system are allowed to read and execute bash, but with SELinux, a security administrator can further specify the subjects that are allowed to execute or read files of type shell_exec_t in policy files. It seems reasonable that a security engineer may not want to permit a web server to execute a shell in case the web server is vulnerable to a remote code execution attack.
One side effect of SELinux’s use of extended attributes is that SELinux is not as useful for protecting objects on file systems that do not support extended attributes, like NFS mounts prior to NFSv4.
Because of the complexity and power of SELinux, I’ll point you to Red Hat’s SELinux User’s and Administrator’s Guide for more detailed information.
SMACK – Simplified Mandatory Access Control
Simplified Mandatory Access Control (SMACK), like SELinux, is an attribute-based MAC implementation and was the second LSM developers merged into the Linux kernel (as part of the 2.6.24 release). Unlike SELinux, SMACK was designed for embedded systems and to be simpler to administer. SMACK is the default MAC implementation in Automotive Grade Linux and Tizen.
AppArmor
AppArmor is another MAC implementation which was originally developed by Immunix and merged into the kernel as part of the 2.6.36 release. AppArmor is the primary MAC implementation on Debian-based systems.
The most notable difference between AppArmor and SELinux, besides the reduced tooling and complexity, is that it is path-based and not attribute-based.
Path-based implementations come with some pros and cons. On the plus side, policies based on paths can protect files on any file system since extended attributes are not required for storing security context information. Rules can also be specified for files that may not exist yet since the path can be stored in the profile without the need to label an actual file or directory. The most commonly cited negative is that, due to the ability to create hard links, there may be multiple paths that refer to the same physical file. The security policy for a single file can be different depending on the path used to reach it which might open unexpected security holes.
TOMOYO
TOMOYO is, like AppArmor, another path-based MAC implementation and was first merged as part of Linux 2.6.30. TOMOYO is designed to protect embedded systems by allowing security administrators to record all user-mode process interactions during testing, which can then be used to generate policies that restrict interactions to only those seen during development / testing. When systems protected with TOMOYO are placed in the hands of untrusted users or in hostile environments, the user-mode processes should then be constrained to only perform previously observed actions, simplifying policy generation.
LoadPin
LoadPin, merged in Linux 4.7, is a “minor” LSM that ensures all kernel-loaded files (modules, firmware, etc) originate from the same file system, with the expectation that such a file system is backed by a read-only device. This is intended to simplify embedded systems that don’t need any of the kernel module signing infrastructure / checking if the system is configured to boot from read-only devices.
Security that is easy to use is more likely to be used, and LoadPin can simplify the process of protecting the kernel from malicious modules for certain types of embedded systems.
Yama
Yama, merged in Linux 3.4, is an LSM intended to collect system-wide DAC security restrictions that are not handled by the core kernel. It currently supports reducing the scope of the ptrace() system call so that a successful attack on one of a user’s running processes cannot use ptrace to extract sensitive information from other processes running as the same user.
SafeSetID
SafeSetID, merged in Linux 5.1, is an LSM used to restrict UID/GID transitions from a given UID/GID to only those approved by a system-wide whitelist.
I think the description of the SafeSetID use case in the kernel sources needs no rewording:
This can be used to allow a non-root program to transition to other untrusted uids without full blown CAP_SETUID capabilities. The non-root program would still need CAP_SETUID to do any kind of transition, but the additional restrictions imposed by this LSM would mean it is a “safer” version of CAP_SETUID since the non-root program cannot take advantage of CAP_SETUID to do any unapproved actions (e.g. setuid to uid 0 or create/enter new user namespace). The higher level goal is to allow for uid-based sandboxing of system services without having to give out CAP_SETUID all over the place just so that non-root programs can drop to even-lesser-privileged uids. This is especially relevant when one non-root daemon on the system should be allowed to spawn other processes as different uids, but its undesirable to give the daemon a basically-root-equivalent CAP_SETUID.
Lockdown LSM

Click to download the full whitepaper!
Merged in Linux 5.4, lockdown is an LSM that implements a “lockdown” feature for the kernel. When lockdown is enabled, a kernel command-line parameter can be used to lockdown the kernel for integrity or confidentiality. When lockdown is set to integrity, features that allow userspace to modify the kernel are disabled. These features include: unsigned module loading, access to /dev/{mem,kmem,port}, access to /dev/efi_test, kexec of unsigned images, hibernation, direct PCI access, raw io port access, raw MSR access, modifying ACPI tables, direct PCMCIA CIS storage, reconfiguration of serial port IO, unsafe module parameters, unsafe mmio, and debugfs access. When lockdown is set to confidentiality, all the integrity protections are enabled plus the disabling of features that allow: userland to extract potentially confidential information from a running kernel such as /proc/kcore access, use of kprobes, use of bpf to read kernel RAM, unsafe use of perf, and use of tracefs.
The lockdown feature could be implemented via SELinux, AppArmor, SMACK, or TOMOYO policy files, but implementing it in a separate stackable LSM with a static policy means it can be used across distributions regardless of the specific MAC implementation in use.
Conclusion
LSMs are not designed to prevent a process from being attacked. Good coding practices, configuration management, and memory safe languages are the tools for that. The protections provided by LSMs do, however, help protect your system from being hacked when an attacker exploits flaws in one of the running programs. They can be an important layer in any defense in depth strategy on Linux systems, and by understanding what protections they provide, you hopefully have a greater appreciation for what systems need to protect and how to implement those protections.







